
Одним из самых важных навыков в переполненном информацией обществе является поиск. Информация, которая нам нужна скорее всего уже есть, осталось только её найти. Об этом (поиске в интернете) даже пишут книги. И всё было бы хорошо, если задача касалась бы только всемирной сети. Однако существует область, где всесильные поисковики недоступны и "погуглить" в принципе невозможно. Речь идёт про нашу память, а точнее про её материальное обеспечение. Дело в том, что при чтении книг, книги эти не копируются в мозг, но отображаются. Причём с потерями.
Наличие библиотеки прочитанных книг не гарантирует оперативность выборки нужных цитат и ассоциативных связей. И вопрос в том, как эту систему связей создать.
Решаемая проблематика
Читая очередной научный труд, руки тянутся к карандашу, к «[разного рода]ноту» (из бумаги или программных). Но зная себя (или не веря в себя), обреченно эти потуги гасишь, поскольку будущее клочков бумаги или даже электронных заметок туманно. Некоторые пропадают навсегда с очередной переустановкой «винды», некоторые всплывают при переезде за шкафом, многие дразнят своей насыщенностью и обилием в конкретной папке, но совершенно не по теме. Намерившись в очередной раз что-либо найти по нужной тематике из прочитанного ранее рискуешь потерять день на разгребание странной сформировавшейся «как бы на эту тему» кучи, а нужного (ну я же точно помню, что-то было!) — не найдешь. Не помогают разного рода метки или теги, рубрики, папки. Сперва ты относил эту мысль к одному разделу, потом приписал к нему другую мысль, когда снова открыл уже и не понятно, как в этот эпизод связан с оригинальным текстом, а главное, этот текст опять приходится снова искать, место в нем эпизода…
На этом фоне кудесниками коры головного мозга предстают образы ученых мужей, способных в монографии оперировать тысячами отсылок и цитат оригиналов, приведенных в списке литературы к ней. С мантрой «надо было меньше пить в юности», с тоской читая о возможностях тренировки памяти, судорожно ищешь какой-то программный «костыль» для компенсации своей убогости сейчас, пока еще память не достаточно окрепла, ничего в результате путного не находя.
Но не все так печально, поскольку есть надежда, что предлагаемое решение позволит не только помочь в конспектировании (хранении), но и создаст некую мозаичную картину представления материала, при чем главное — распространения мозаичного представления этого материала среди потребителей-кооператоров (тема кооперации сейчас актуальна).
Существующие на сегодняшний день решения (вики, поисковики, блокноты) не позволяют реализовать весь требуемый функционал. Требуется некоторое их развитие. Предлагаемая к разработке система хранения информации должна решать эти проблемы.
Предполагаемый алгоритм работы с системой
Далее попытаюсь описать общие планы, как это видится в процессе использования, по механизмам пока идей нет. Открываем на устройстве (планшет, телефон, ПК) программу-клиент. Открываем ресурс (эл.книгу, сайт, свой текст) и начинаем работать с информацией.
1. Все нижеописанные работы только по необходимости, конечно:
1.1. Применяем «Интегральный алгоритм чтения», то есть записываем (возможно, при помощи горячих клавиш — выделил и клавишей внес в соответствующую графу):
Интегральный алгоритм чтения
- Наименование (книги, статьи)
- Автор
- Источник и его данные (год, №)
- Основное содержание, тема
- Фактографические данные (при помощи работ №2 и №3)
- Особенности излагаемого материала, которые, кажутся спорными, критика (при помощи работ №2 и №3)
- Новизна излагаемого материала и возможности его использования в практической работе (при помощи работ №2 и №3)
1.2. К конкретному отрывку применяем «Дифференциальный алгоритм чтения» (так же можно подумать о горячих клавишах)
Дифференциальный алгоритм чтения
- Выделение ключевых слов
- Выявление смысловых рядов
- Выявление цепи значений
1.3. Отнесение отрывка текста к определенному классификатору с использованием работы №2, то есть при
1.4. Добавление своих комментариев по классифицируемой теме 1.5. Добавление ссылок по классифицируемой темеРабота с классификатором
- Выделение ключевых слов
- Выявление смысловых рядов
- Выявление цепи значений
можно их отнести к определенному классификатору, виду работы №1 (фактология, критика, комментарий, особенности, новизна и пр).
1.6. Добавление ассоциаций (не прямое классифицирование) в виде разделов того же классификатора
1.7. Добавление сведений для «процессного мышления», меры процесса, описанного в тексте. (ссылка на начало процесса, временной интервал, ссылка на продолжение процесса)
В результате работы с текстом мы имеем несколько экземпляров «объектов хранения». Каждый объект состоит из (реквизиты):
Реквизиты объекта хранения
- Наименование (строка)
- Автор (ссылка на объект справочника Авторы)
- Источник и его данные (строка)
- Основное содержание, тема (ссылка на объект справочника Классификатор)
- Набор слов, содержание (строка)
- Ссылку на родительский объект (такой же объект хранения), этим выстраивается иерархия
- Тип объекта (Оригинал, смысловой блок, комментарий, процесс, ассоциация, критика, практика, что-то еще в списке для выбора)
- Вид объекта (текст, видео, аудио, ссылка, что-то еще в списке для выбора)
- Дата, время (для процессов или по необходимости)
- Геолокация, для представления на карте, группировки по странам и т.п. (координаты)
2. Использование объектов хранения
2.1. Обзорное
при упоминании об источнике (ресурсе, объекте), с которым мы уже работали, появляется возможность напомнить себе, в чем там было дело. Картина такая: открываем внутренний поиск, выбираем тип «оригинал», вид (например текст), автора, открываем из появившегося списка нужный объект. Форма обзорного просмотра должна содержать максимум информативности при минимуме усложнений восприятия :). То есть реквизиты и под ними каким-то образом упорядоченные дочерние объекты хранения. По которым также видна детализация проведенной работы. Скорее всего по интегральному алгоритму надо выдавать сначала фактологические дочерние объекты хранения, потом особенности, критика, новизна, ссылки и пр. Если это составная часть процесса, выделять отдельно.
2.2. Мозаичное
через объект хранения можно посмотреть его место в системе классификатора. Представляю это так: по ссылке из формы объекта переходим на форму представления конкретного классификатора и видим место объекта среди других объектов хранения одно с ним уровня иерархии, и если позволяет размер поля - родительские уровни иерархии.
2.3. Процессное
через объект хранения можно посмотреть его место в общем течении процесса
В принципе, процесс и классификатор можно объединить в одну сущность. Тогда пункты 2.2 и 2.3 сливаются.
3. Кооперация с другими исследователями
3.1. Помощь
возможно делиться ссылками на объекты хранения. Для этого (пока вижу так) необходим доступ к интернет, серверная часть программы с http сервером. Получив ссылку, товарищ может :
3.1.1. скачать объект, внедрив его в свою систему классификаторов (назначением определенных при скачивании) или заимствовав одновременно со скачиванием классификатор(ы) помощника
3.1.2. открыть «мозаичную форму» или "процессную форму» объекта (см.2.2) и увидеть местоположение его в системе помощника. При этом становятся доступными все соседние объекты хранения помощника для скачивания
Возможность вывода содержимого базы, «мозаичную форму» в виде иерархического представления в виде страницы ссылок. При нажатии на ссылку происходят действия 3.1. Либо средствами серверной части программы с http сервером, либо публикацией на распространенные движки по правилам конвертации.
3.3. Поиск
При поиске обычными для интернета средствами мы находим страницу представления (3.2) и видим ее в структуре классификатора
Если представить структуру ссылки в системе определенным образом, то появляется возможность указывать в строке поиска конкретные места конкретных классификаторов,что отсеивает большинство спама поисковых систем.
Система заведомо предполагается без единой базы данных для безопасности, независимости, производительности. Но с возможностью построения независимых выборных «обзоров» и пр. на своих носителях.
Можно продумать систему сканирования базы на предмет битых ссылок с выдачей рекомендаций к пересмотру и многое другое.
Сейчас просто необходимо эту систему создать, и работа уже ведется над принципами организации внутренних ссылок.
От вас просьба покритиковать систему вообще и «узкие места» узлов, принципов.
Система предполагается быть полностью бесплатной, без всяких намеков на нехватку продуктов питания у автора (см. рассказ Экономы).
Первоначальная структура:
Самое простое пока — 2 таблицы:
1. Объекты хранения 2. Связи объектов
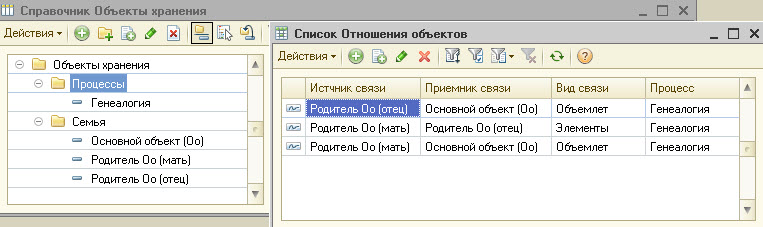
При такой логике выводить можно будет в форму представления эти объекты следующим образом:
В середине фрейма ряд одноуровневых объектов (пока только «Оо», потом если ему добавить «Брат Оо», он выведн будет справа)
Вверху фрейма ряд объемлющих объектов, в данном контексте — родители «Оо»
Внизу фрейма ряд подчиненных объектов (там будут выведены дети «Оо», если их ввести в базу) Вот пример выборки из базы, представление будет, конечно, не таким, это просто представление логики размещения:

43 комментария
Естествоиспытатель, мне кажется, что вы упустили из виду самый главный вопрос. Поиск информации, в первую очередь, подразумевает поиск ИСТИНЫ. В вашем описании об этом нет ни слова.
Все ваши предложения сводятся к одному: КАК СТРУКТУРИРОВАТЬ и ИДЕНТИФИЦИРОВАТЬ информацию. Однако, ЛОЖНАЯ ИНФОРМАЦИЯ — это тоже ИНФОРМАЦИЯ, причем ее может быть многократно БОЛЬШЕ чем ИСТИННОЙ информации. Попробуйте сами себе ответить на вопрос, зачем структурировать и идентифицировать ЛОЖЬ, тратя на это ресурсы (причем ложной инфы может быть бесконечно много, а ресурсы всегда ограничены)?
Поиск бредятины №… в куче бредятины, это может увлекательное занятие, но как будете использовать этот результат в жизни (на практике)? Или может вся суть (цель) и состоит в том, что бы в холостую израсходовать ресурсы?
- О, бредятина, однако...
не кладет в эту систему.
Не понятно, в чем проблема. За руку никто ни кого тянуть не будет.
Система у каждого своя, в помощь хранения своего накопленного опыта.
Вас же телефон не заставляет звонить.
кого цитатами глушить собираетесь, коллега?
Потрудитесь или прочитать тему, которую комментируете и попытаться самому себе ответить на этот вопрос, или не писать, если не хочется читать. Ведь вас никто ни к чему не принуждает, вы кроме иронии можете что-либо предложить?
Это кому-нибудь надо, кроме вас? Я вот видел, как управляют огромной компанией с помошью тетрадки в клеточку и видел как разваливался лидер рынка решивший заменить эксель на жди ди эдвардс ….
Не в ит-инструменте дело …
Впрочем, ктож вам запретит для себя что-то делать ))) Я начал с того, что это уже видел не раз, и здесь, в том числе, поэтому — дежавю )))
Вы придумали проблему и кинулись её решать, еще и посторонних пытаетесь втянуть …. Пройдите второй этап ПФУ, может это не фактор давления, а ваша иллюзия? Может есть другие факторы, на которые лучше употребить ваша аналитические способности? ТЗ, я вижу, вы грамотно пишете! ))))))
Как вариант (избежать этого) вносить только то что отвечает вашей профессии, таким образом и создаются очень полезные сайты, например. и труд не будет напрасным и в профессии всё будет «под рукой», так же полезно если пишешь работу по определенной тематике, поэтому важно структурирование по тематике.
Обязательны (ведь это электронный справочник) действующие перекрестные ссылки.
Если интересно мнение не по сути вопроса, то:
Полезный способ систематизировать свою психику и деятельность, никого не слушайте (не обращайте внимание на колкости в комментариях) систематизируйте! :)
Многие комментирующие правы, и можно воспользоваться принципом предлагаемым авторским коллективом для связи с подсознанием и ИВУ вплоть до ИНВОУ, но одно другому не мешает :)
В данный момент ИНВОУ имеет для меня вот такое описание.
А вот интересно, вы сами поняли что сказали? Ну-ка
скажитесообщите мне всё что сказали ранее без лингвистических конструкций :)))) пиктограмму нарисуйте что-ли :))) фигвам какой что-ли :)))Если и после этого непооняятнооо, то даю ссылки:
1.
2.
Спасибо всем. Колкости в моём варианте не прокатывают, когда имеешь представление о биоэнергоинформационных процессах.
Конечно, инструменты нужны не всем, по разным причинам.
Конечно, инструменты нужны, по разным причинам
Имеющийся инструментарий не решает описанных в статье задач.
Использовать будущий инструмент нужно осознано, тогда не будет подмена ответственности пользователя ответственностью изготовившего инструмент.
Обсуждение нужно изначально максимально абстрагировать, чтобы уйти от перехода на личности. Когда будет понятна структура, можно детализировать
Поэтому ни о каком техническом задании пока речи быть не может.
Попробую
1. Описать наиболее абстрактную модель.
2. Как можно больше примеров использования
29 декабря 2016г., 19:22:
Сам столкнулся с проблемой систематизации знаний и источников информации при изучении большого объёма информации.
Поэтому создал такую систему на базе VBA и SQL.
Система имеет в первом этапе своего развития:
- классификацию источников информации
- реестр авторов информации с подробными описанием и выходом на внешние источники
- реестр каналов распространения информации
- реестр источников информации с подробными описанием и выходом на внешние источники
- реестр тегов (смысловых словоформ и их кратких сокращений)
- практически полную интеграцию с Word документами
- автоматическое конвертирование строки текста в название закладки Word документа с помощью тегов
- режим формирования конспекта источника информации на базе Word документа
- реестр программ чтения (как раньше в школах задавали на лето) с фиксированием и отслеживанием проработанных источников информации
я сделал просто полный список работ ВП в Libre Calc'е (аналог экселя):
дата, название, имя файла, поле прочитал/не прочитал
И заполняю потихоньку.
Самое простое пока — 2 таблицы:
1. Объекты хранения
2. Связи объектов
В конце статьи добавил рисунок с примерными данными в таких таблицах.
При такой логике выводить можно будет в форму представления эти объекты следующим образом:
В середине фрейма ряд одноуровневых объектов (пока только «Основной объект (Оо)», потом если ему добавить «Брат Оо», он выведн будет справа)
Вверху фрейма ряд объемлющих объектов, в данном контексте — родители «Оо»
Внизу фрейма ряд подчиненных объектов (там будут выведены дети «Оо», если их ввести в базу)
В конце статьи добавил рисунок, демонстрирующий выборку по такой логике.
1. «Прочитанная книга» — «Выписка 1» — «Объемлет» — «Классификатор процесса 1»
2. «Прочитанная книга» — «Выписка 2» — «Объемлет» — «Классификатор процесса 1»
3. «Прочитанная книга» — «Выписка 3» — «Объемлет» — «Классификатор процесса 2»
Потом в форме представления записей можно удобно развернуть ряд выписок,
слева на право будут сами выписки, иконки или мини-окна с возможностью прочитать текст с возможностью прокрутки по горизонтали
выше их будут иконки объемлющих их объектов, в нашем случае — «Прочитанная книга», ее можно будет раскрыть в отдельном окне,
То есть представление связанных объектов одного ряда по выбранному «процессу» и показ связей этого ряда с объемлющими процессами и подчиненными, с возможностью перейти на вышестоящий ряд или нижележащий…
Удобства возникнут только когда в такую форму представления появится возможность добавлять новый объект, в нашем случае — «Выписка 4».
При этом дальнейшее представление объектов показывает их взаимосвязи с объектами других уровней.
Просили покритиковать. Критикую.
1. Система как некоторый индивидуальный инструмент превращается в сложный блокнот. ИМХО она начинает приобретать некоторый смысл только как сеть. Что-то типа торрент-сети с возможность взаимного встраивания и связывания контента.
2. Как мне кажется Вы изначально пытаетесь создать слишком глубокую детализацию связей. Встраивание очередного объекта с каждым новым объектом начинает превращаться в АД чем дальше тем больше.
3. Почти не рассмотрена система валидации данных и связей. Пока вообще нет никаких мыслей.
4. Совсем не рассмотрена система допуска к критической части контента. Тоже нет мыслей. Нужны критерии.
Это просто первые мысли которые всплыли по прочтению.
Пока мозаика напоминает мне интернет глазами его создателей во времена появления HTML. Задумка милая была. Что вышло — видим все сами сейчас.
1. Без такого сложного блокнота, все прочие блокноты сейчас «очень тяготят». Не представляете, как тяжело браться за исследовательскую работу, читать, смотреть. И чем больше в жизни уходишь от потребительства, тем сложнее, поскольку не можешь просто так сидеть и «потреблять», читать и «потреблять», желание внести тут же это в «систему» сильно давит на мозг, вплоть до отказа просмотра и чтения чего-либо…
А делиться, «взаимно встраивать» — второй уровень этой системы, верно.
2. «Слишком» — возможно. Я ведь выстраиваю «по максимуму», конфигурируя модель, но можно на начальных этапах сделать определенные «заглушки», чтобы не превратить «встраивание нового объекта в ад» и постепенно наращивать степени «валидации». Их так можно и сделать выдачей сообщений, что так и так, здесь будет такая-то функция… или проверьте пока вручную то-то.
Для остального нужны фактические данные, которые появятся после начала прорисовки структуры, от которой пока только идея. Ну, а что , нормально же пошло? Так потихоньку доковыляем до «Информатория» (ну, не специально, до сих пор я эти вещи не связывал… да и в рассказе немного другая версия — «Транзакторий», надеюсь электронного концлагеря не будет)
Попробую развить свою мысль.
Вы задаете параметры системы как справочник. (Оч умный блокнот) Для меня такая система близка к бесполезной. Основных причин вижу две:
1. При первичном прочтении того или иного материала я принципиально не веду никаких записей и пометок. Мне для нормального прочтения требуется погружение. Как и для работы над чем-то. Тишина и покой. Иначе эффективность ниже плинтуса.
2. При повторном прочтении, в материале или ищется некий второй(третий) смысл и в этом случае см пункт 1. Или материал сразу используется только как справочник.
То есть для меня лично такая система была бы полезна только в том случае если бы первичную массу данных в нее вносил-бы не я или процесс внесения был бы КРАЙНЕ прост. Звучит эгоистично, но как уж есть.
с_01:
.01. встретил публикацию:
https://mediamera.ru/post/25036
.02. затронула тем, что о подобном тоже думал.
.03. при этом хочется сказать автору — что тоже шёл в начале от проектирования системы.
.04. однако потом упёрся в сложность реализации запрошенного, когда применять уже прямо сейчас хочется.
.05. в итоге пошёл с другой стороны.
.06. взял развитие блокнота — SublimeText — который позволяет создавать проекты (указывать папку и вся её структура становиться видна в дереве рядом с текстом открытого файла).
.07. опираясь на этот инструмент из своей практики стал выделять части/компоненты.
.08. в начале были файлы просто текстов/заметок — которые хоть и держали мысли и помогали частично их организовывать, но в длительной перспективе терялись и не давали чего-то желанного.
.09. следующим витком стал файл заметок.
.10. при этом:
.каждая заметка имеет свой номер.
.каждая заметка должна быть краткой мыслью.
.заметки разбиваются на секции.
.в заметки тяну всё, что кажется подходящей к теме — ссылки, размышления, описание текущей ситуации.
.заметки неизменяемы — раз записав и дав ей номер — такой она и остаётся.
.11. далее, из заметок (их пересматривая) стал стремиться выделять:
.структуру факторов.
.вектор целей.
.и изредка способы/методы.
.12. при этом получается концепция.
.13. концепция может переписываться заново — поэтому ей добавил версионирование, похожее на семантическое версионирование.
.14. далее — из заметок и концепции бывает надо оформить какие-либо тексты/повествования — например сообщения в переписке — поэтому появилась секция с файлами результатов.
.15. ещё далее — появились цепочки из пар вопрос-ответ.
.16. и последнее введение в эту систему — наброски — когда это ещё не законченный текст/мысль, но набросок где-то сделать надо.
.17. при этом внутри используется адресация к элементам — например в тексте заметки указываю что такую-то цепочку решил начать.
с_02:
.18. таким образом от практики складывалась система фиксации размышлений.
.19. и сразу-же применял то, о чём думал.
.20. сейчас, когда практика применения устаканилась и я вижу положительный эффект от неё — возникло пожелания написать более специализированный инструмент — просмотрщик таких файлов, который добавлял бы некоторые удобства.
.21. процесс разработки отражаю в подобных заметках — сейчас собираются документы тут.